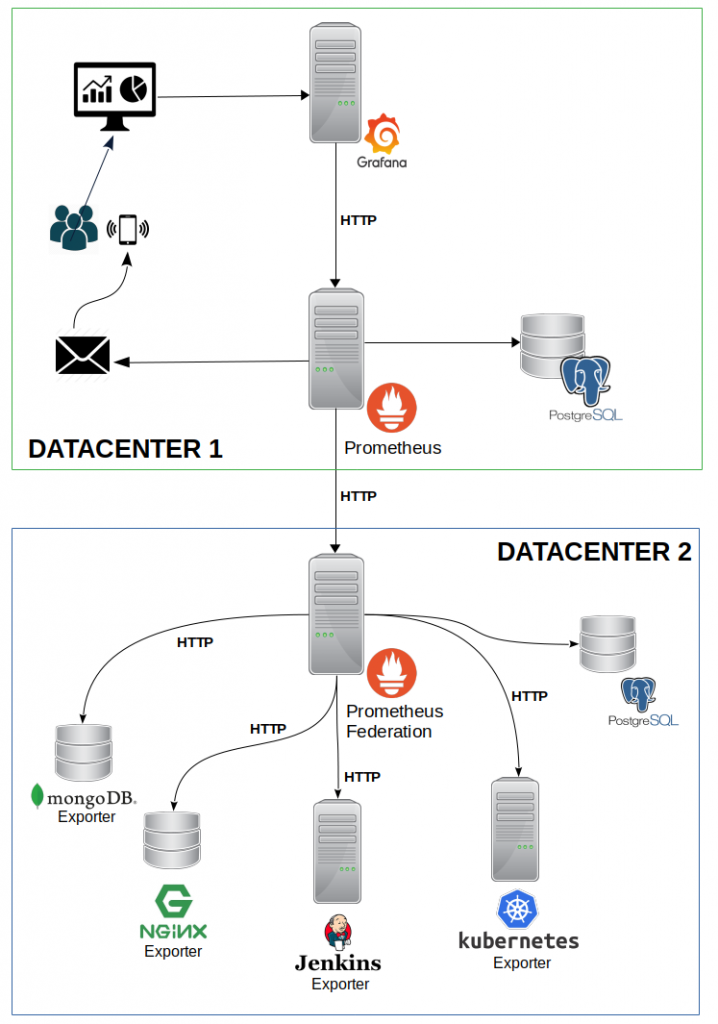
No cenário ao lado, foi realizada a implementação de um ambiente de monitoramento entre 2 datacenters diferentes. O Datacenter 1 (DC1) é composto pelo servidor Prometheus Master com um banco de dados PostgreSQL com TimescaleDB e Alert Manager habilitado para enviar alertas por e-mail e um servidor Grafana para exibição das métricas em tempo real através das Dashboards. O Datacenter 2 (DC2) é composto pelo servidor Prometheus Federation, banco de dados PostgreSQL e várias aplicações com os seus devidos exporters instalados. O Prometheus federation busca em cada um dos servidores de aplicações as métricas disponibilizadas pelos exporters via push HTTP e armazena todas elas no banco de dados PostgreSQL. Dessa maneira, temos um monitoramento centralizado dentro do DC2. O Prometheus Master busca a todo momento no Prometheus federation todas as métricas das aplicações que foram coletadas, e com isso, todas as informações ficam centralizadas no DC1. O Grafana verificar as métricas do Prometheus Master disponibiliza-as em painéis com visões em tempo real e sempre que ocorrer um problema, o Alert Manager enviará os alertas por e-mail para as contas definidas. Em caso de perda de comunicação entre os datacenters, o Prometheus federation continua coletando as métricas das aplicações, e assim que a comunicação estiver acontecendo novamente, o Prometheus master irá buscar no federation todas as métricas que estão faltando devido ao período de indisponibilidade, garantindo assim um monitoramento sem perda de informações e evitando ‘buracos’ nos Dashboards do Grafana. Caso também existam servidores de monitoramento Zabbix, é possível fazer a integração para que o Grafana receba também as métricas de infraestruturas coletadas pelo Zabbix centralizando as métricas de todo o ambiente de TI em uma única ferramenta, facilitando o gerenciamento e análise de incidentes, onde tudo pode ser acompanhado através de gráficos e dashboards intuitivas.