
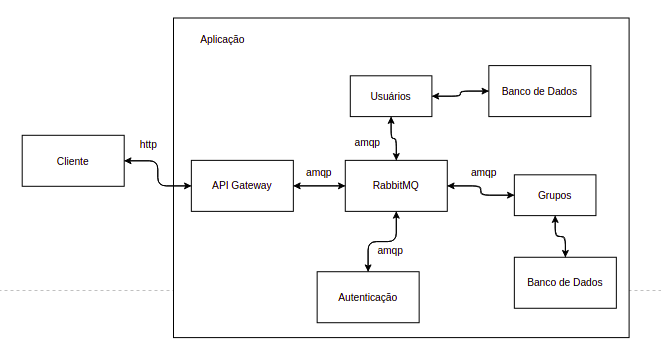
Podemos exemplificar o uso de Docker para criação de sistemas distribuídos em micro serviços com uma simples aplicação de gerenciamento de usuários.
Esta aplicação seria composta pelos seguintes serviços:
- Serviço de Usuários (Python);
- Serviço de Grupos (PHP);
- Serviço de Autenticação (Node);
- Gateway de API (Java);
- Banco de Dados (Postgres);;
- Fila distribuída (RabbitMQ)
Cada item da lista acima tem sua própria imagem e portanto são aplicações distintas umas das outras. O Gateway de API iria expor uma API Rest através de end points que despacham mensagens para o(s) serviço(s) requisitado(s) utilizando a fila como canal de mensageria. Esses serviços iriam consultar o banco de dados aonde armazenam informações (cada um desses serviços pode ter seu próprio banco de dados) e retornam as informações ao Gateway também através de fila. Como o cliente interage com o sistema através do Gateway a forma de operação assíncrona com que a aplicação trabalha está escondida atrás desse Gateway o que permite a reestruturação da aplicação sem quebra de contrato.



